
Optimiser les performances de sérialisation dans Django Rest Framework
Quand on choisit Python, Django ou Django Rest Framework (DRF), ce n’est généralement pas pour leur vitesse brute. Python reste avant tout le choix de l’ergonomie et du confort de développement — le langage que l’on privilégie pour livrer rapidement des fonctionnalités complexes plutôt que pour gagner quelques microsecondes.
Privilégier la productivité n’est pas un problème en soi. La grande majorité des projets n’a pas besoin d’une performance millimétrée, mais d’un code de qualité livré dans les temps.
Cependant, cela ne signifie pas que la performance est négligeable. Comme nous allons le voir, des gains majeurs peuvent être obtenus avec un peu d’analyse et quelques ajustements stratégiques.
Le problème : les performances du ModelSerializer
Il y a quelque temps, nous avons constaté des lenteurs inexpliquées sur l’un de nos principaux endpoints API. Puisque cet endpoint interrogeait une table volumineuse, notre premier réflexe a été d’incriminer la base de données.
Pourtant, même sur des jeux de données réduits, les performances restaient médiocres. En creusant davantage, nous avons identifié le véritable coupable : les sérialiseurs de Django Rest Framework.
Contexte : Pour ce benchmark, nous utilisons Python 3.7, Django 2.1.1 et Django Rest Framework 3.9.4.
L’approche “brute” : une fonction simple
Le rôle d’un sérialiseur est de transformer un objet complexe en un dictionnaire simple (et inversement). En essence, c’est une opération triviale. Testons une fonction basique qui transforme une instance User en dict :
from typing import Dict, Any
from django.contrib.auth.models import User
def serialize_user(user: User) -> Dict[str, Any]:
return {
'id': user.id,
'last_login': user.last_login.isoformat() if user.last_login is not None else None,
'is_superuser': user.is_superuser,
'username': user.username,
'first_name': user.first_name,
'last_name': user.last_name,
'email': user.email,
'is_staff': user.is_staff,
'is_active': user.is_active,
'date_joined': user.date_joined.isoformat(),
}Créons un utilisateur test pour notre benchmark :
>>> from django.contrib.auth.models import User
>>> u = User.objects.create_user(
>>> username='hakib',
>>> first_name='haki',
>>> last_name='benita',
>>> email='me@hakibenita.com',
>>> )Pour notre test, nous utilisons cProfile. Afin d’isoler la sérialisation des accès disque ou réseau, nous traitons un utilisateur déjà chargé 5 000 fois :
>>> import cProfile
>>> cProfile.run('for i in range(5000): serialize_user(u)', sort='tottime')
15003 function calls in 0.034 secondsCette fonction simple prend 0,034 seconde pour 5 000 opérations.
Le ModelSerializer de DRF
DRF propose le ModelSerializer pour automatiser cette tâche. Voici une implémentation classique pour notre modèle User :
from rest_framework import serializers
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = [
'id',
'last_login',
'is_superuser',
'username',
'first_name',
'last_name',
'email',
'is_staff',
'is_active',
'date_joined',
]Lançons le même benchmark :
>>> cProfile.run('for i in range(5000): UserModelSerializer(u).data', sort='tottime')
18845053 function calls (18735053 primitive calls) in 12.818 secondsVerdict : 12,8 secondes, soit environ 2,56 ms par utilisateur. C’est 377 fois plus lent que notre fonction manuelle.
L’analyse montre qu’une part énorme du temps est consommée par functional.py. ModelSerializer s’appuie sur la fonction lazy de Django pour gérer les validations et les métadonnées, ce qui alourdit considérablement le processus.
Le ModelSerializer en lecture seule (Read Only)
DRF n’ajoute les logiques de validation que pour les champs éditables. Pour tester l’impact de ce mécanisme, passons tous les champs en read_only :
from rest_framework import serializers
class UserReadOnlyModelSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = [
'id',
'last_login',
'is_superuser',
'username',
'first_name',
'last_name',
'email',
'is_staff',
'is_active',
'date_joined',
]
read_only_fields = fieldsRésultats :
>>> cProfile.run('for i in range(5000): UserReadOnlyModelSerializer(u).data', sort='tottime')
14540060 function calls (14450060 primitive calls) in 7.407 secondsOn tombe à 7,4 secondes, soit une amélioration de 40 %. C’est mieux, mais encore loin de la performance optimale.
Le sérialiseur classique (Serializer)
Pour mesurer le coût réel de l’automatisation du ModelSerializer, utilisons un Serializer standard en définissant manuellement les champs :
from rest_framework import serializers
class UserSerializer(serializers.Serializer):
id = serializers.IntegerField()
last_login = serializers.DateTimeField()
is_superuser = serializers.BooleanField()
username = serializers.CharField()
first_name = serializers.CharField()
last_name = serializers.CharField()
email = serializers.EmailField()
is_staff = serializers.BooleanField()
is_active = serializers.BooleanField()
date_joined = serializers.DateTimeField()Benchmark :
>>> cProfile.run('for i in range(5000): UserSerializer(u).data', sort='tottime')
3110007 function calls (3010007 primitive calls) in 2.101 secondsLe gain est massif : seulement 2,1 secondes. C’est 60 % plus rapide que le Read Only ModelSerializer et 85 % plus rapide que le ModelSerializer par défaut.
Le constat est clair : la magie du ModelSerializer a un prix.
Résumé des performances
| Type de Sérialiseur | Temps (secondes) |
|---|---|
| UserModelSerializer | 12.818 |
| UserReadOnlyModelSerializer | 7.407 |
| UserSerializer | 2.101 |
| UserReadOnlySerializer | 2.254 |
| serialize_user (Fonction brute) | 0.034 |
Pourquoi une telle lenteur ?
La plupart des articles parlent d’optimiser l’ORM (select_related, prefetch_related), mais peu traitent de la sérialisation pure. Sans doute parce qu’on ne s’attend pas à ce que transformer un objet en JSON soit le goulot d’étranglement.
Tom Christie (créateur de DRF) soulignait déjà en 2013 :
“Vous n’avez pas toujours besoin d’utiliser des sérialiseurs.” Pour les vues ultra-critiques, n’hésitez pas à utiliser directment
.values()dans vos QuerySets.
Améliorations de Django et DRF
Une grande partie de la lenteur provenait de la fonction lazy dans Django. Elle utilisait un cache pour les proxies de classes, mais un bug rendait ce cache inopérant, forçant une reconstruction coûteuse à chaque appel.
Ce bug a depuis été corrigé. Voici l’impact des correctifs (Avant vs Après) :
| Sérialiseur | Avant | Après | Évolution |
|---|---|---|---|
| UserModelSerializer | 12.818 | 5.674 | -55% |
| UserReadOnlyModelSerializer | 7.407 | 5.323 | -28% |
| UserSerializer | 2.101 | 2.146 | +2% |
| UserReadOnlySerializer | 2.254 | 2.125 | -5% |
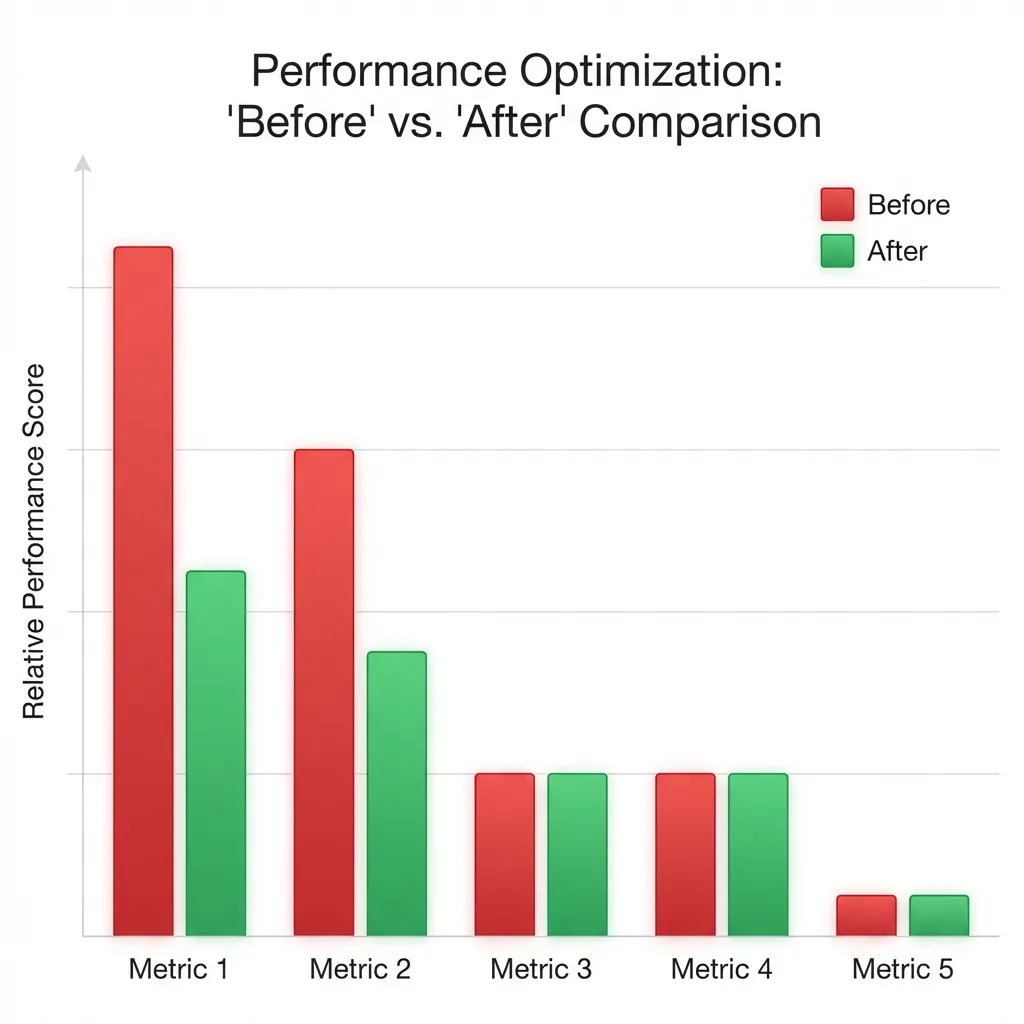
Résultats clés :
- Le temps du
ModelSerializerest divisé par deux. - Le
ModelSerializeren lecture seule gagne 30 %.
Ce qu’il faut retenir
- Maintenez vos dépendances à jour : Les correctifs de Django et DRF apportent des gains de performance “gratuits”.
- Utilisez des
Serializerclassiques pour les endpoints critiques : Évitez le surcoût duModelSerializerquand chaque milliseconde compte. - Abusez du
read_only=True: Si vous n’avez pas besoin de valider une donnée en entrée, marquez-la en lecture seule pour alléger le traitement.
Bonus : Automatiser les bonnes pratiques
Pour éviter que nos développeurs n’oublient ces optimisations, nous avons mis en place un check système Django :
# common/checks.py
import django.core.checks
@django.core.checks.register('rest_framework.serializers')
def check_serializers(app_configs, **kwargs):
import inspect
from rest_framework.serializers import ModelSerializer
import conf.urls # Force l'import de tous les sérialiseurs.
for serializer in ModelSerializer.__subclasses__():
# Ignorer les applications tierces
path = inspect.getfile(serializer)
if path.find('site-packages') > -1:
continue
if hasattr(serializer.Meta, 'read_only_fields'):
continue
yield django.core.checks.Warning(
'ModelSerializer must define read_only_fields.',
hint='Set read_only_fields in ModelSerializer.Meta',
obj=serializer,
id='H300',
)Désormais, un oubli génère un avertissement immédiat lors de l’exécution de manage.py check.
Cet article démontre qu’en matière de performance, ce sont souvent les petits détails d’implémentation qui font les plus grandes différences.